

À l'occasion de la Journée nationale de la protection des données se pose la question des IA reposant sur les grands modèles de langage. Elles s’entraînent à partir des données saisies par les utilisateurs. Celles-ci sont parfois sensibles et confidentielles, mais l’IA ne sait pas faire le tri. Comment s'assurer qu'elles ne seront pas divulguées ?
au sommaire
Imaginez que des éléments de votre vie personnelle s'affichent dans une réponse d'un chatbot comme ChatGPTChatGPT chez n'importe qui. C'est malheureusement possible car le modèle de langage s'enrichit de ce que ses utilisateurs saisissent. C'est notamment le cas pour les entreprises pour lesquelles des employés saisissent des données financières confidentielles ou des codes sources propriétaires sans se douter que le modèle va les ingurgiter et sans doute les ressortir à terme. D'ailleurs, des recherches montrent que le taux de fuite de données de ce type n'est pas anecdotique. Pour ChatGPT, il y aurait 158 incidents de ce type pour 10 000 utilisateurs par mois.
C'est pour cette raison que des réglementations commencent à émerger au sujet de la protection des données dans le cas des intelligences artificielles. En décembre, 2023 l'Union européenne s'est accordée pour mettre au point des règles harmonisées au sujet de l'intelligence artificielle. Elles prévoient une obligation de transparencetransparence et la publication d'une synthèse des données d'entraînement utilisées pour les modèles. Outre la réglementation qui reste de toute façon en décalage par rapport au rythme de l'innovation, il existe des solutions pour protéger les données et paradoxalement, c'est l'IA elle-même qui peut assurer cette tâche.

Des données synthétiques
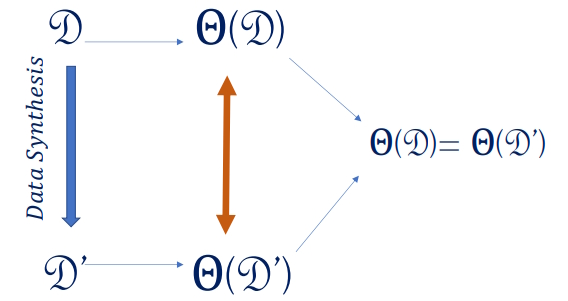
Ainsi, il est possible d'indiquer à l'IA quelles sont les données qui doivent être protégées. Cette manipulation peut d'ailleurs être automatisée encore une fois par l'IA. De même, en dehors de l'utilisation de chatbots, cette IA permet de contrôler si des informations sensibles sont susceptibles de sortir du réseau d'une entreprise, par exemple. L'autre solution technique consiste à réaliser l'apprentissage des IA avec des données synthétiques. Il s'agit de données créées artificiellement et qui se substituent à des données réelles pour les protéger. Ces données sont justement créées par l'IA. Ce sont des sosies des données, plus anonymes, qui vont avoir le même effet que les données réelles pour l'IA.
Concrètement, en médecine par exemple, au lieu d'alimenter l'IA avec des radios réelles montrant des tumeurstumeurs, une IA va générer des radios équivalentes pour entraîner un système de machine learning. Ces données synthétiques auront le même effet et permettront à l'IA d'aider le travail des radiologues tout aussi efficacement. Le hic, c'est que faire générer ces données synthétiques nécessite de créer une IA spécifique et cela a un coût énorme. De fait, la protection des données au niveau des IA n'est pour le moment pas une priorité.









