

Il aura fallu onze mois à l'intelligence artificielle de Google pour maîtriser, puis dominer des humains à Quake III Arena, un jeu qui mêle stratégies à plusieurs et combats en un contre un. Une vraie prouesse car les cartes de jeu évoluent en permanence et ne peuvent pas être mémorisées par l'IA.
au sommaire
Des chercheurs du laboratoire d'intelligence artificielle DeepMind, à Londres, viennent de publier les résultats de leurs recherches sur l'apprentissage automatique et les jeux vidéo. Après avoir réussi à maîtriser le jeu StarCraftStarCraft II en mode « un contre un » avec son intelligence artificielle AlphaStar, l'équipe a poussé les recherches plus loin avec des parties en équipe dans QuakeQuake III Arena.
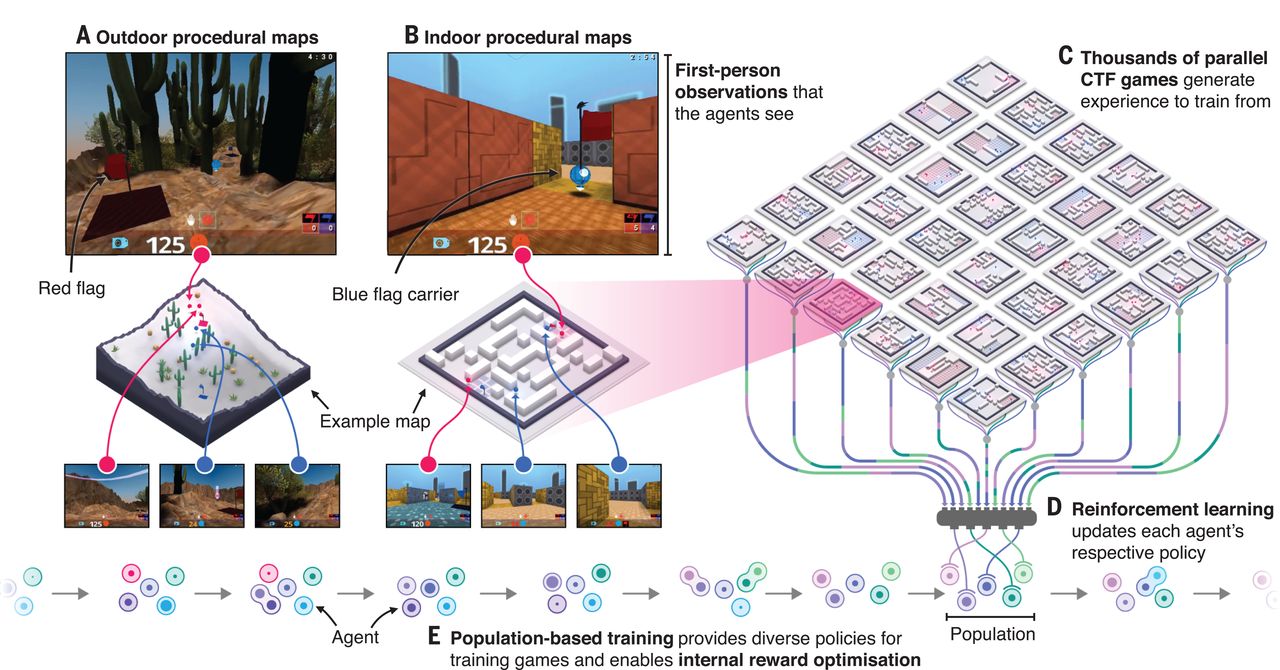
Les chercheurs se sont intéressés plus particulièrement au mode « capture the flagflag », la capture du drapeau où les règles sont très simples. Les joueurs sont répartis en deux équipes, et doivent travailler ensemble pour ramasser le drapeau dans la base adverse et le ramener dans la leur, tout en protégeant leur propre drapeau.
Les chercheurs de DeepMind ont donc créé une équipe composée « d'agents » indépendants, chacun devant apprendre et mettre en place ses propres stratégies tout en coopérant avec ses coéquipiers. Pour corser le tout, et empêcher que l'IA ne crée des techniques trop spécifiques à certaines configurations, la carte est générée aléatoirement à chaque partie.
Une intelligence artificielle qui apprend à jouer sans la moindre consigne
Les agents doivent apprendre seuls à voir, bouger, coopérer et se battre. Le seul retour dont ils disposent pour juger de leurs performances est lorsque leur équipe a gagné ou non. Leur apprentissage s'est basé sur la technique du deep learning, avec des réseaux neuronaux, et 450.000 parties du jeu. Les chercheurs ont pu observer la mise en place de stratégies par leurs agents avec, par exemple, un neuroneneurone qui est activé lorsque le drapeau est pris dans la base de l'agent, ou un autre qui s'active si l'un de ses coéquipiers tient le drapeau ennemi.
Les chercheurs ont organisé un tournoi avec 40 joueurs humains, choisis de manière aléatoire pour être ennemis ou coéquipiers avec les agents. L'IA ayant un temps de réaction très largement supérieur aux humains, les chercheurs ont ralenti les agents pour permettre une compétition équilibrée.
Malgré cela, les agents ont écrasé les joueurs humains, en remportant 79 % des parties contre des adversaires ayant un très bon niveau. Le score passe à 88 % contre des humains de niveau moyen. Les participants au tournoi ont même indiqué dans un sondage que les agents jouaient de manière plus collaborative que les joueurs humains.

Une capacité à collaborer sans communication directe
Contrairement aux humains, les agents ne pouvaient pas communiquer en dehors du jeu. Leur méthode de collaboration consistait donc simplement à réagir au mieux aux actions de leurs coéquipiers. Cela signifie qu'en permettant aux agents d'échanger leurs stratégies, ils pourraient encore améliorer leurs performances. Le système actuel est tellement efficace qu'il a donné de très bons résultats sur la version complète de Quake III Arena, avec des cartes utilisées dans des parties professionnelles, de nouveaux modes multijoueur, et plus de bonus en jeu.
Ces résultats montrent la progression de la recherche sur l'intelligence artificielle dans les univers virtuels. Cependant, les chercheurs n'étudient pas les jeux vidéo comme une fin en soi, mais comme point de départpoint de départ grâce à un environnement simplifié par rapport au monde réel. Des telles avancées pourraient ensuite être étendues aux robots, par exemple pour déplacer les marchandises dans les entrepôts et leur permettre de travailler en groupe.
L'IA de Google DeepMind apprend le travail d'équipe en jouant à Quake III Arena
DeepMind a enseigné à plusieurs IA à collaborer aussi bien entre elles qu'avec des humains en jouant au célèbre jeu vidéo Quake III Arena grâce à une technique d'apprentissage renforcé.
Publié le 04/07/18 par Marc ZaffagniMarc Zaffagni
Les jeux vidéo multijoueur de tir à la première personne représentent un défi à la fois considérable et extrêmement bénéfique pour le développement d'une intelligence artificielle. Pourquoi ? Parce qu'ils sont à l'image des sociétés humaines, où chacun poursuit ses objectifs personnels tout en étant immergé dans un réseau collaboratif par le travail, les loisirs, les sports...
Apprendre à une IA à être à la fois autonome et capable d'utiliser son expérience pour collaborer efficacement avec un autre programme, voire un humain : voilà précisément ce qu'a réussi DeepMind. La filiale de GoogleGoogle spécialisée en intelligence artificielle vient de présenter ses derniers travaux sur ses « agents coopératifs complexes » formés à l'aide du jeu Quake III Arena.
Ce jeu vidéo culte propose un mode de jeu type capture de drapeau. Deux équipes s'affrontent avec un objectif simple : capturer le drapeau de l'adversaire tout en protégeant le sien. Les stratégies à mettre en œuvre sont illimitées. Pour une IA, les qualités requises sont multiples : savoir coopérer tout en affrontant l'équipe adverse et s'adapter en permanence au stylestyle de jeu qu'on lui oppose. DeepMind a ajouté une complication en changeant la disposition de la carte du jeu à chaque partie afin de forcer ses IA à développer des stratégies généralistes plutôt que de mémoriser la carte.
Dans cette vidéo de DeepMind, quatre IA s’affrontent dans une partie de capture de drapeau sur Quake III Arena. © DeepMind
450.000 parties de Quake III Arena
Pour parvenir à ce résultat, DeepMind a eu recours à l'apprentissage par renforcement (en anglais reinforcement learning) qui est une forme d'apprentissage automatique inspirée par le comportementalisme. Cette technique permet une prise de décision à partir d'informations dynamiques changeantes. L'équipe DeepMind a créé un algorithme d'apprentissage par renforcement nommé For the Win qui a servi à entraîner en parallèle plusieurs IA en jouant 450.000 parties de Quake III Arena.
Le logiciel n'avait pas une connaissance préalable des règles du jeu. D'une partie à l'autre, les IA ne recevaient qu'un seul signal pour renforcer leur apprentissage : si leur équipe avait gagné ou non. Chaque agent intègre son propre système de récompense qui lui permet de définir ses objectifs dans le jeu.
Lors d'un tournoi organisé contre 40 joueurs humains, les équipes constituées uniquement d'IA ont systématiquement battu les équipes 100 % humaines et affichaient un taux de victoire de 95 % face à des équipes mixtes Hommes-IA. Par ailleurs, DeepMind indique que les participants humains interrogés sur leur expérience ont estimé que les intelligences artificielles étaient plus collaboratives que leurs semblables.
Ce dernier point est très important dans une perspective future où les Hommes et les IA seront amenés à travailler ensemble. Reste que l'environnement dans lequel DeepMind a mené son expérimentation est évidemment beaucoup moins complexe que le monde réel. Nous n'en sommes qu'aux prémices de ce rapprochement Hommes-machines, inéluctable...
Code Promo Cdiscount
Ce qu’il faut
retenir
- L’apprentissage par renforcement est l’un des axes de développement pour l’intelligence artificielle.
- DeepMind a entraîné plusieurs IA afin qu’elles soient à la fois capables d’atteindre des objectifs individuels et de collaborer entre elles ou avec des humains.





 ? © phonlamaiphoto, Adobe Stock")


















