







 à la théorie des réseaux")


au sommaire
Nous verrons ici que la composante la plus forte montre des propriétés mathématiques identiques dans les données de la biologie et de la finance. Ainsi, le premier vecteur propre V1 et le vecteur degrés Me sont très proches.


© Agsandrew Fotolia
Étant donné la forte similarité des données, il convient d'exploiter la composante la plus conséquente de la matrice. En fait, elle a un comportement similaire dans les données de biologie et de finance.
Plus spécifiquement, que ce soit en biologie ou en finance, on observe que la valeur propre λ1 est très, très grande par rapport à λ2, pouvant être 1.000 voire 10.000 fois plus élevée ! Ce comportement implique en fait que les composantes du premier vecteur propre V1 sont très proches des composantes du vecteur degrés Me, on dira que V1 est très proche de Me, à un facteur de renormalisation des composantes de Me près, que l'on note 1/ llMell. Ainsi, on peut écrire la formule d'égalité des vecteurs suivante :
V1 = Me/ llMell + E (2)
où E est appelé vecteur erreur. La théorie de l'algèbre linéaire permet d'estimer les composantes du vecteur E, et de démontrer qu'elles sont très petites devant les composantes du vecteur degrés renormalisées Me/ llMell. Cette caractérisation des petites composantes du vecteur E donne un sens au fait que λ1 soit très élevé par rapport à λ2, puisque, ainsi :
V1 ≈ Me/ llMell

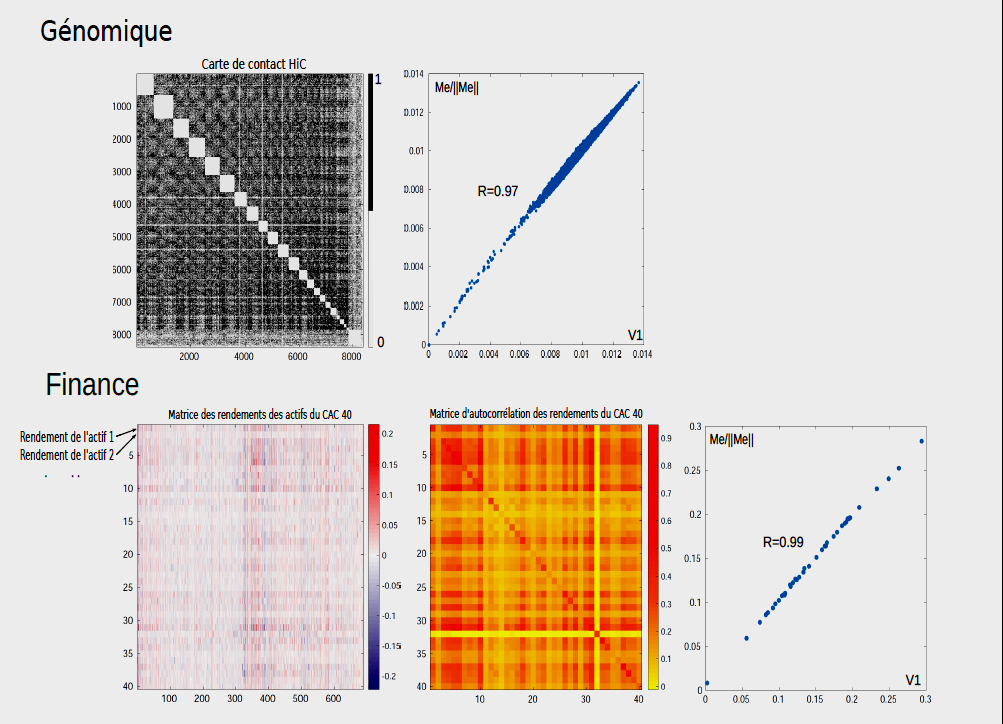
Figure 6 - En haut, il est représenté une carte de contact, suivi du graphique V1 versus Me/ llMell. En bas, nous voyons la matrice des rendements du CAC 40, puis la matrice de corrélation, avec le graphique V1 versus Me/ llMell. Dans les deux cas, les droites sont quasiment parfaites, comme en témoignent les coefficients de régression linéaire très proches de 1. © Julien Riposo - Tous droits réservés
Concernant les cartes de contact en biologie, la somme de toutes les lignes de la je colonne donne le nombre de contact(s) physique(s) que la partie numéro j de l'ADNADN a avec l'ensemble des autres parties. On peut prouver que si la valeur propre λ1 est aussi élevée, c'est parce qu'il y a un certain nombre de contacts très corrélés entre eux : la structure tridimensionnelle locale de l'ADN dans le noyau est corrélée à toute autre structure d'une autre localisation, révélant une longue portée spatiale de corrélation. Par ailleurs, si un scientifique de données (ou data scientist) voulait effectuer une analyse des vecteurs propres, il lui serait déconseillé de tenir compte du premier vecteur propre V1 qui est redondant avec la matrice M elle-même, puisqu'il se rapproche du vecteur degrés Me que l'on obtient facilement à partir de la matrice M comme expliqué plus haut.
En finance, cette notion de corrélation fait tout autant surface : si la « valeur de marché » (c'est ainsi que l'on nomme λ1 en finance) est aussi grande, c'est parce que les produits financiers constituant la matrice sont globalement très corrélés. Par exemple, si l'on forme une matrice d'autocorrélation avec des actifs d'un même indice boursierindice boursier (comme les actifs du CAC 40, du DAX ou ceux du S&P 500), qui sont tous très corrélés entre eux, la valeur de marche sera très élevée. Par ailleurs, l'établissement d'une méthode statistique de gestion de portefeuille à l'aide, entre autres, de l'équation (2) fait l'objet de recherches actuelles.
Nous voyons ici une tentative d'illustration de mathématiques de données : il aurait peut-être été impossible d'établir de façon rigoureuse un rapprochement entre les vecteurs V1 et Me sans l'avoir déjà vu dans des données. Ce rapprochement a permis d'interpréter des données de domaines bien distincts que sont la biologie et la finance, bien que les mathématiques soient les mêmes. Mais il y a bien d'autres domaines encore que ce résultat peut intéresser, comme l'analyse spectrale d'un cliché de paysage, ou encore l'étude des corrélations des nœudsnœuds d'un réseau.

par Julien Riposo











