

L’ADN permet de stocker d’immenses quantités de données dans un très faible volume et sur des millions d’années. Mais de nombreuses étapes de la fabrication d’ADN demeurent encore manuelles, et c'est un puissant frein à son développement commercial. Des ingénieurs de Microsoft ont bricolé un « traducteur » automatique qui convertit les bits numériques en lettres ADN, avec à peine 10.000 dollars de matériel.
au sommaire
Alors que le volume de données produit dans le monde pourrait atteindre 175 zettaoctets en 2025 selon IDC (International Data Corporation), les datacenters engloutissent une énergie de plus en plus colossale. Depuis plusieurs années, les scientifiques essayent donc de trouver une solution alternative pour archiver cette montagne d’informations.
Il en existe une disponible de façon universelle sur notre Planète : l'ADNADN. En 2016, les équipes du Molecular Information Systems Lab (MISL) de l'université de Washington et de MicrosoftMicrosoft avaient ainsi réussi à encoder un clip vidéo d'environ 200 Mo sur de l'ADN -- ils sont depuis parvenus à un nouveau record de 1 Go. Début 2018, les chercheurs du Waterford Institute of Technology ont, de leur côté, fait la démonstration d'encodage et décodage d'un message dans une bactériebactérie E.coli.
Vers l'automatisation du processus ?
Mais alors que le séquençageséquençage et la synthèse d'ADN ont fait de gros progrès ces dernières années, bon nombre des étapes intermédiaires restent manuelles. Un gros frein au développement commercial du stockage. « Vous imaginez des personnes arpentant toute la journée le centre de donnéescentre de données avec des pipettes ? C'est bien trop coûteux et sujet à l'erreur humaine, sans compter l'espace nécessaire », met en avant Chris Takahashi, chercheur à l'école de sciences et technologie Paul Allen de l'université de Washington. L'automatisation du processus est donc la clé pour rendre le système abordable. Et c'est justement ce que vient de réussir l'équipe de Takahashi en collaboration avec les ingénieurs de Microsoft.
Un convertisseur qui a coûté moins de 10.000 dollars
Les chercheurs ont réussi à fabriquer une machine capable de transformer automatiquement des données numériquesnumériques (suites de 0 et de 1) en séquences ADN (bases azotéesbases azotées A, C, TT et G). Le prototype, qui a coûté à peine 10.000 dollars, est réalisé avec des bouteilles en verre où sont fabriqués des brins d'ADN synthétique, et un séquenceur d'Oxford Nanopore pour les décoder et les reconvertir en données numériques.
Lors d'une démonstration, la machine a réussi à traduire le mot « hello » en ADN. L'algorithme développé par Microsoft convertit d'abord les bits en bases ADN, qui sont obtenus à l'aide d'un synthétiseur en ajoutant des produits chimiques. Les cinq octetsoctets de « hello » (01001000 01000101 01001100 01001100 01001111) peuvent ainsi être stockés dans 1 mg d'ADN, soit moins de 4 microgrammes sous la forme exploitable par séquençage.


Le processus est, pour l'instant, incroyablement lent : 21 heures pour convertir 5 octets ! Mais, les chercheurs assurent avoir déjà trouvé un moyen de le diviser par deux. « Notre objectif est de mettre au point un système qui, pour l'utilisateur final, ressemble à n'importe quel autre service de stockage cloud, où les données sont envoyées dans un datacenter ADN, puis sont reconverties en bits lorsque le client en a besoin », explique Karin Strauss, chercheuse principale chez Microsoft.
De l’informatique solide à l’informatique liquide
Mais quel est l’intérêt de l’ADN par rapport à nos bonnes vieilles puces en siliconesilicone ? D'une part, un gain significatif de place : selon Microsoft, la totalité de l'information contenue dans un datacenter pourrait tenir dans un petit cube de la taille d'un dé. D'autre part, l'ADN perdure plusieurs millions d'années, là où les composants informatiques ne résistent guère plus de 10 ans. Adopter massivement ce stockage biologique va cependant nécessiter une totale révolution : contrairement aux puces, l'ADN est stocké sous forme liquide, ce qui nécessite des technologies complètement différentes.
Par ailleurs, de gros progrès doivent encore être accomplis. Microsoft estime ainsi qu'il faudra atteindre une vitesse de conversion d'environ 100 Mo par seconde pour être viable commercialement. Le coût de la fabrication d'ADN doit également baisser. La start-upstart-up française DNA Script affirme ainsi pouvoir produire 1.000 nucléotidesnucléotides en une journée avec son « imprimante ADN ». Le MISL (Molecular Information Systems Lab) travaille, quant à lui, sur des logicielslogiciels capables d'effectuer une recherche de données à partir des moléculesmolécules d'ADN, comme par exemple retrouver une image de chat ou une phrase d'un texte.
L'ADN sera-t-il le support de stockage ultime de l'humanité ?
Article de Laurent SaccoLaurent Sacco publié le 22/08/2012
La quantité d'information que l'humanité produit ne cesse de grandir et sa préservation pour les générations futures devient problématique. Une possible solution explorée depuis quelque temps fait intervenir son stockage avec de l'ADN. Un groupe de chercheurs américains vient d'illustrer tout le potentiel de la méthode en enregistrant un livre entier dans seulement 1 picogramme d'ADN.
Notre monde devient de plus en plus une société de l'information via les données transitant par les ordinateursordinateurs et InternetInternet, conséquences des travaux d'Alan Turing. Photos, vidéos, textes, données numériques de toutes sortes voient leur quantité doubler chaque année du fait de l'activité d'Homo sapiensHomo sapiens. Mais quelle part de cette information sera disponible pour la prochaine génération et comment la stocker sous une forme durable et peu encombrante ? Car l'humanité a produit en 2011 environ 1021 octets d'information et ce chiffre aura été multiplié par 50 en 2020. Comment transmettre des dossiers médicaux, des musiques ou d'autres œuvres d'art à l'aide de supports pouvant durer un siècle au moins par exemple ?
Le travail sur ce problème de stockage des archives de l'humanité se fait depuis quelques années comme en témoigne, par exemple, le M-Disc. Mais l'une des techniques les plus prometteuses semble celle basée sur de l'ADN. Cette idée est explorée depuis un certain temps et un article récemment publié dans Science vient d'illustrer toute la puissance du stockage de l'information digitale à l'aide de la mythique molécule de la vie, dont la structure a été élucidée par Watson et Crick il y a de cela presque 60 ans.
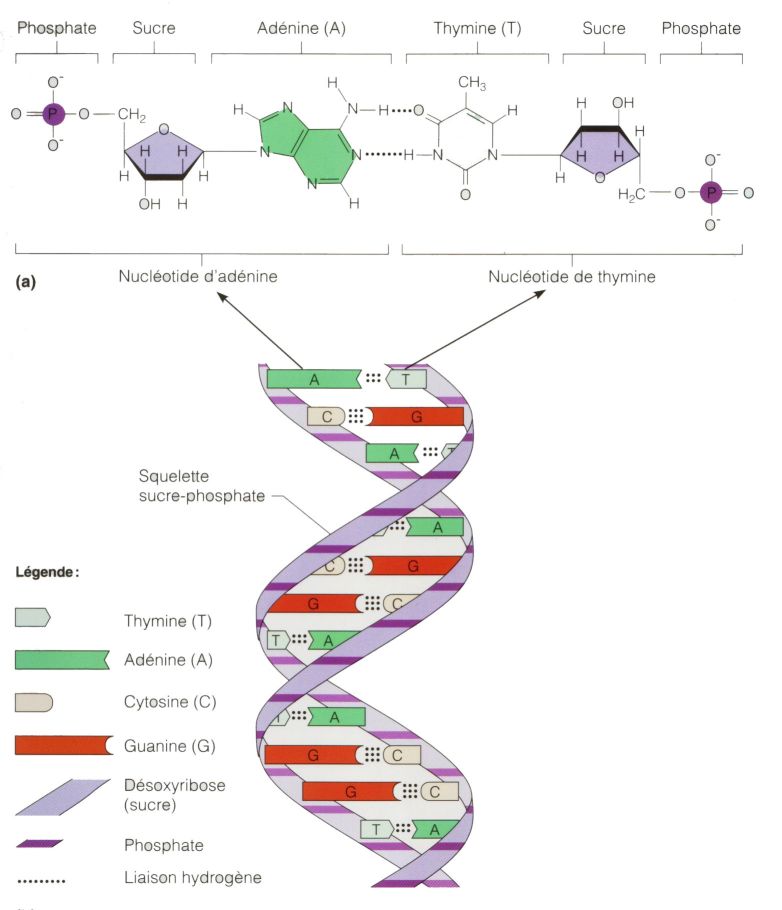
. Sa structure est celle d'une double hélice composée de deux brins complémentaires. Chaque brin est constitué d'un enchaînement de quatre nucléotides A, G, C et T. L'information génétique est codée par l'ordre dans lequel s'enchaînent ces quatre nucléotides. © Site de Biologie du réseau Collégial du Québec")
L'un des auteurs de l'article de Science n'est autre que George Church, bien connu pour ses travaux sur la biologie synthétique. C'est son livre, Regenesis: How Synthetic Biology Will Reinvent Nature and Ourselves, qui a été enregistré puis lu à l'aide d'une nouvelle technique, sur un support constitué de brins d'ADN. Le livre lui-même contient 53.426 mots, 11 images et un programme en JavaScript constituant une quantité d'information de 5,37 mégabits. Un millionième de millionième de gramme d'ADN a suffi pour assurer son stockage. Le précédent record avec de l'ADN était de 7,920 bits. On a donc presque multiplié par 1.000 la quantité d'information stockée.
Un million de gigabits par centimètre cube d'ADN
Ce volume d'information n'a rien d'extraordinaire en lui-même. Mais la densité de stockage est spectaculaire puisqu'elle est équivalente à 5,5 pétabits ou 1 million de gigabits par centimètre cube. C'est très largement supérieur à celle des disques dursdisques durs et plus de 10 milliards de fois la densité de stockage d'un CDCD. Toutefois, le stockage avec de l'ADN obtenu par les chercheurs ne peut pas concurrencer les disques durs car on ne peut écrire, lire ou effacer à volonté l'information sur le support.
Pour stocker l'information, il est nécessaire de synthétiser des brins d'ADN dans lesquels les données en binairebinaire sont enregistrées sous forme de séquences de nucléotides adénineadénine (A), thyminethymine (T), cytosinecytosine (C) et guanineguanine (G). Chaque brin d'ADN est un fragment de l'information totale entreposée sur un support en verre. Un code, lui aussi contenu dans la séquence de nucléotides, indique à quelle partie du fichier, par exemple celui contenant le livre de George Churh, correspond le brin d'ADN. Il faut enfin utiliser la technique de séquençage de l’ADN et traiter l'information obtenue à l'ordinateur pour retrouver l'information initiale. Un processus guère pratique et bien évidemment coûteux. C'est pourquoi le stockage avec de l'ADN est plutôt destiné à faire de l'archivage de données. Il ne semble pas voué à remplacer les mémoires de nos ordinateurs dans la vie quotidienne.
La technique des chercheurs américains ne faisant pas intervenir de l'ADN présent dans des cellules vivantes (il y aurait des risques de mutation altérant l'information enregistrée), et comme l'ADN hors de ces dernières peut se conserver intact des milliers d'années à température normale, il semble probable que les archives du futur de l'humanité seront bel et bien constituées d'ADN. Cela laisse songeur lorsque l'on sait qu'il en est de même pour l'information génétiquegénétique des espècesespèces vivantes.
Ce qu’il faut
retenir
- Microsoft et l’UW ont mis au point une machine capable de transcrire des bits informatiques en base ADN et vice-versa.
- L’automatisation du processus est une étape clé vers le développement commercial du stockage ADN.
- L’ADN permet de conserver des archives sur des millions d’années et prend beaucoup moins de place.





. © Google")













, Michael H. Wong (UC Berkeley) ; Traitement d’images : Joseph DePasquale (STScI)")
")


