 s’attaque à la synthèse vocale avec une réussite tout aussi spectaculaire. © Sergey Nivens, Shutterstock")
 s’attaque à la synthèse vocale avec une réussite tout aussi spectaculaire. © Sergey Nivens, Shutterstock")
au sommaire
Un jour, il est assez probable que vous puissiez converser au téléphone avec un robot sans même vous en apercevoir. C'est ce que laisse entrevoir la dernière innovation de la firme britannique DeepMind. Après avoir battu un champion du monde de jeu de Go grâce à son programme d’intelligence artificielle (IAIA) AlphaGoAlphaGo, cette filiale de GoogleGoogle s'est attaquée à un autre domaine, celui de la synthèse vocale.
WaveNet, sa nouvelle IA, est capable d'imiter la parole humaine avec une efficacité 50 % supérieure aux technologies existantes. Le système fonctionne en apprenant à former les ondes sonoresondes sonores que produit la voix humaine. Lors de tests à l'aveugle, des auditeurs ont classé WaveNet largement devant les solutions de synthèse vocale par concaténation et par modélisationmodélisation paramétrique qui sont aujourd'hui les plus répandues.
La synthèse vocale par concaténation est celle utilisée par les assistants virtuels que l'on trouve sur smartphones, les SiriSiri, CortanaCortana et autres Assistant Google. Leurs voix respectives proviennent de l'enregistrement de séquences courtes d'une voix humaine qui sont combinées pour former des phrases. Le résultat est assez naturel, mais le problème est que toute évolution du système nécessite d'enregistrer de nouvelles séquences (écouter un exemple de synthèse vocale par concaténation créé par Google).

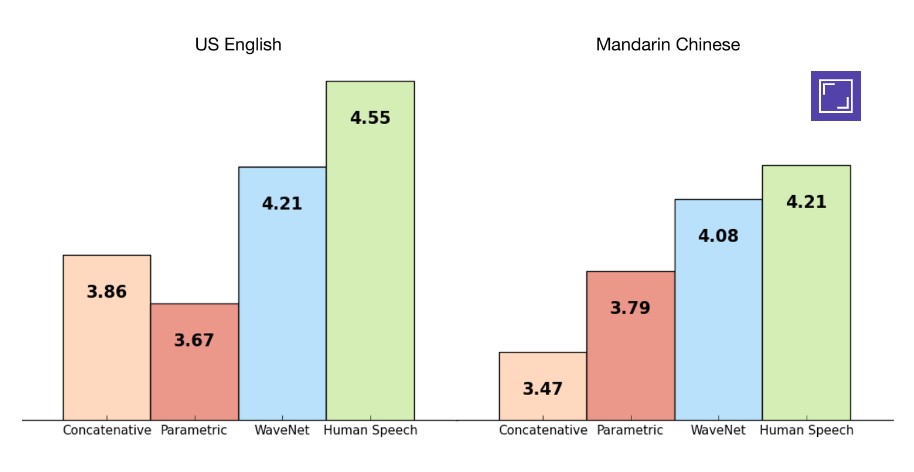
Ces graphiques illustrent le résultat de 500 tests à l’aveugle menés par DeepMind pour évaluer la performance de WaveNet. Était noté sur une échelle de 1 à 5 le niveau de réalisme des séquences audio entendues en anglais et en mandarin. On constate que l’IA se classe juste après la parole humaine et loin devant les autres systèmes de synthèse vocale existants. © DeepMind
La synthèse vocale de Google écoute et imite
La synthèse vocale par modélisation paramétrique consiste à générer une voix artificielle par ordinateur en se basant sur des règles de grammaire et de prononciation. L'avantage est qu'il n'y a pas besoin d'une source humaine. Mais le résultat manque pour le moins de naturel, comme on peut en juger dans cet autre extrait de Google.
WaveNet se sert d'une voix humaine comme référence, mais au lieu de la sectionner pour composer ses phrases, l'intelligence artificielle en extrait les ondes sonores dont elle se sert comme modèle pour créer des voix différentes. En gros, cette IA écoute puis imite. Comme on peut l'entendre dans cet extrait, WaveNet surclasse effectivement les autres méthodes de synthèse vocale. Et le système ne se cantonne pas qu'à la voix puisqu'il peut aussi faire de la musique et sait par exemple jouer du piano.
Toutefois, malgré l'apparente facilité qui se dégage de cette démonstration, il ne faut pas s'attendre à la voir arriver de sitôt dans les smartphones, ordinateurs et autres robots. En effet, WaveNet nécessite une puissance de calcul encore trop importante pour une machine individuelle. Mais on peut faire confiance à Google pour trouver le moyen d'exploiter cette technologie dès que possible.
Découvrez les comparatifs et guides d'achats Smartphones
Retrouvez tous nos articles sur la rubrique guides d'achat smartphone :
- Meilleurs Smartphones 2024 - Test et Comparatif
- Meilleurs Smartphones 5G 2024 - Test et Comparatif
- Meilleurs Smartphones Apple 2024 - Test et Comparatif
- Les meilleurs smartphones à moins de 800 € : lequel choisir en 2024 ?
- Les top smartphones haut de gamme à moins de 700 €
- Les meilleurs smartphones à moins de 600 € : lequel choisir en 2024 ?







 ? © phonlamaiphoto, Adobe Stock")
















